Production-ready Agent 到底差在哪(vs demo)
Demo agent 上不了 production 的 6 個硬傷:
| 硬傷 | Demo agent | Production agent |
|---|---|---|
| 監控 | ❌ 跑完就沒了 | ✅ 全程 telemetry |
| 重試 | ❌ 失敗就掛 | ✅ exponential backoff |
| Budget | ❌ 跑到帳單爆 | ✅ 4 層成本守門 |
| Audit | ❌ 出事查不到 | ✅ 完整 log + 可重現 |
| Secret 管理 | ❌ API key 寫死 | ✅ Vault / Secrets Manager |
| Rollback | ❌ 出包慘 | ✅ 版本控制 + canary deploy |
多數 agent 教學只示範 demo 能跑,但真正上 production 時,監控、重試、預算、稽核、secret 管理與 rollback 才是差距。
🚀 4 階段部署升級路徑
部署階段不該一次跳到最複雜的架構,而是依照使用者數、風險、成本與運維能力逐步升級。
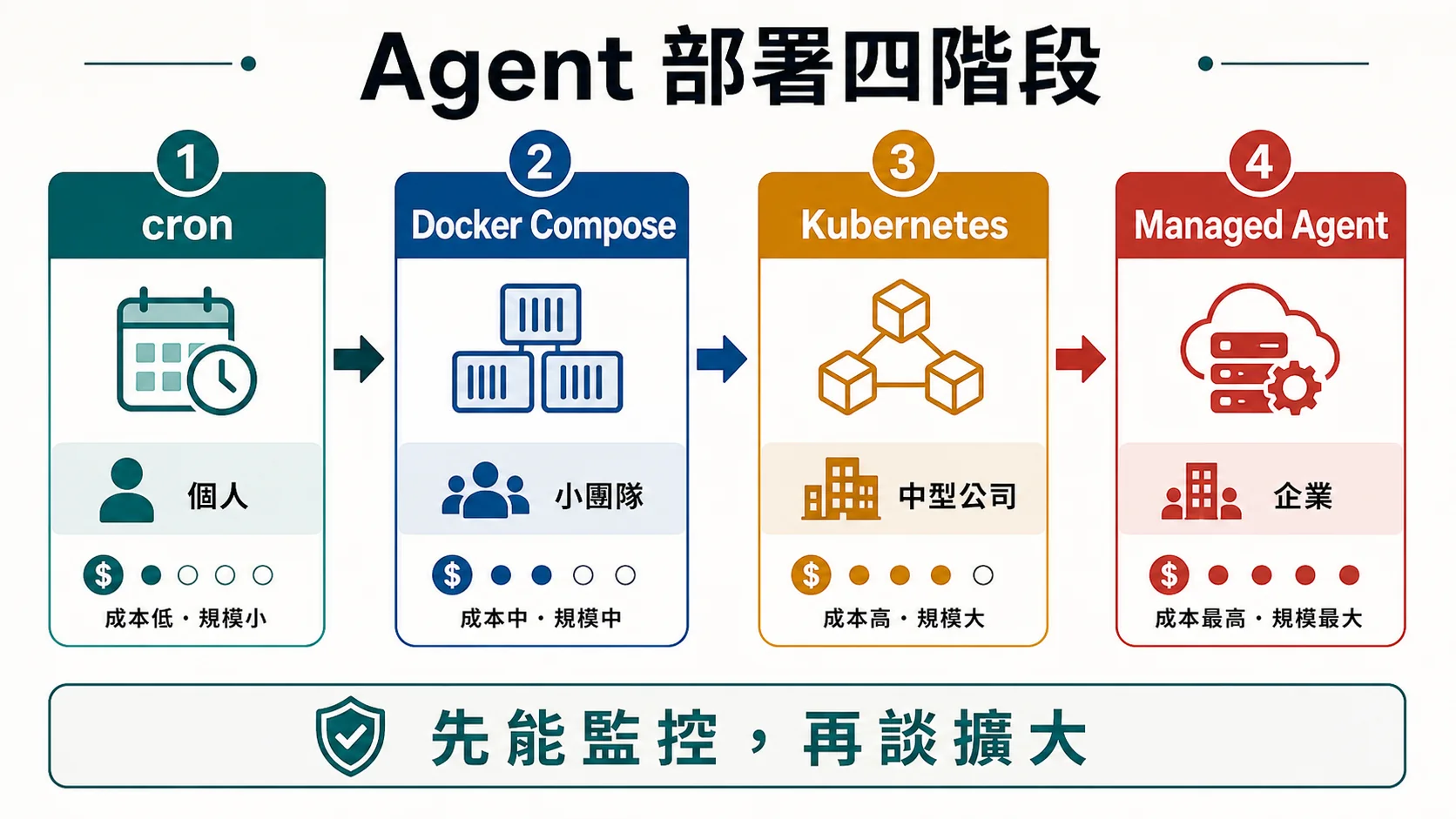
階段 1:cron + 系統服務(個人,$0-5/月)
適合誰:個人開發者、Solo 顧問、第一年 production
技術負擔:極低(只需 cron + shell script)
月成本:$0-5(LLM API 費 + 電費)
macOS:用 launchd
<!-- ~/Library/LaunchAgents/com.mason.daily-triage.plist -->
<plist>
<dict>
<key>Label</key><string>com.mason.daily-triage</string>
<key>ProgramArguments</key>
<array>
<string>/Users/mason/projects/daily-triage/run.sh</string>
</array>
<key>StartCalendarInterval</key>
<dict><key>Hour</key><integer>5</integer><key>Minute</key><integer>30</integer></dict>
<key>StandardOutPath</key><string>/Users/mason/logs/triage.log</string>
<key>StandardErrorPath</key><string>/Users/mason/logs/triage-err.log</string>
</dict>
</plist>啟用:launchctl load ~/Library/LaunchAgents/com.mason.daily-triage.plist
Linux:用 cron
# crontab -e
30 5 * * * /home/mason/projects/daily-triage/run.sh >> /home/mason/logs/triage.log 2>&1Windows:用 Task Scheduler
圖形化介面 + 排程——WSL2 內 cron 也可,但需 WSL 啟動才生效**。
為什麼 cron 是 90% 個人 agent 的最佳解
5 個壓倒性優勢:
- 0 學習曲線(已存在的工具)
- 0 額外成本(系統內建)
- debug 容易(log 寫 file 即可)
- 可移植(任何 macOS / Linux 都能跑)
- 不依賴雲端(完全離線可跑)
cron 的天花板
何時該升級:
- 每小時要跑多次(cron 最細 1 分鐘間隔,但密集任務會搶資源)
- 需要 web UI 監控(cron 沒原生 UI)
- 多人共享(cron 是個人專用)
- 需要 retry 機制(cron 自己沒有,要自己寫)
實務上,許多個人排程型 agent 長期停在階段 1 也很合理,因為穩定、可觀察、低成本比架構複雜度更重要。
階段 2:Docker compose(小團隊,$10-50/月)
適合誰:小團隊、需要部署到 VPS、需要 sandbox 隔離
技術負擔:中(需懂 Docker、docker-compose)
月成本:$10-50(VPS + LLM API 費)
為什麼 Docker
3 個壓倒性優勢:
- 可移植(同樣容器在 dev / staging / prod 跑)
- Sandbox 隔離(agent 改了什麼不會影響主機)
- 環境一致(避免「我電腦上能跑」**問題)
Dockerfile 樣板(Python + uv + Claude Agent SDK)
FROM python:3.12-slim
WORKDIR /app
# 安裝 uv(快速 pip 替代)
RUN pip install uv
# 複製依賴清單
COPY pyproject.toml uv.lock ./
# 安裝依賴
RUN uv sync --frozen
# 複製專案
COPY . .
# 環境變數(從 docker secret 帶)
ENV ANTHROPIC_API_KEY=""
# 啟動 agent
CMD ["uv", "run", "python", "agent.py"]docker-compose stack(3-container)
# docker-compose.yml
version: '3.8'
services:
agent:
build: .
environment:
- ANTHROPIC_API_KEY=${ANTHROPIC_API_KEY}
secrets:
- api_key
volumes:
- ./data:/app/data
- ./logs:/app/logs
depends_on:
- redis
- langfuse
redis:
image: redis:7-alpine
volumes:
- redis-data:/data
langfuse:
image: langfuse/langfuse:latest
environment:
- DATABASE_URL=...
ports:
- "3000:3000"
secrets:
api_key:
file: ./secrets/api_key.txt
volumes:
redis-data:Secret 管理
❌ 不該做:API key 寫在 .env 然後 commit(.gitignore 也擋不住意外)
✅ 該做:
- docker secrets(本地簡單)
- HashiCorp Vault(企業正式)
- AWS Secrets Manager / GCP Secret Manager(雲端)
階段 3:Kubernetes(中型公司,$200-2000/月)
部署提醒:多數 agent 不需要一開始就上 K8s。若團隊規模、併發量與隔離需求還不明確,K8s 很容易變成額外運維負擔。
需要 K8s 的 3 個信號
- High concurrency(同時跑 100+ 個 agent instance)
- Multi-tenant(不同客戶資料隔離)
- 跨 cluster(多 region / 多 cloud)
不需要 K8s 的常見情境
- 個人 agent(cron 即可)
- 小團隊 5-20 人(Docker compose 即可)
- 單一 agent 服務(VPS + Docker 即可)
Kubernetes 選型
選項 1:Kagenti(Anthropic 系統)——官方支援 Claude Agent SDK 選項 2:Agent Sandbox(Kubernetes 2026/03 推出)——通用 agent runtime 選項 3:GKE Agent Engine(Google Cloud)——managed K8s + agent 整合
mTLS / SPIFFE / Zero-trust 入門
Agent 跨服務通訊需要身份驗證:
- SPIFFE:通用身份框架
- mTLS:互相驗證的 TLS(client + server 都有憑證)
- Zero-trust:永不信任、永遠驗證
詳細企業合規 → 台灣中小企業 AI 戰略
階段 4:Anthropic Managed / Vertex Agent Engine(企業,按 hour 計)
適合誰:企業合規嚴 / 上線時程壓力大 / 不想自己運維
月成本:按 session hour 計($0.08/hr for Claude Managed)
託管省掉的 4 件事
- Session 管理(自動處理 long-running agent state)
- Sandbox(自動隔離)
- Auto-retry(內建錯誤恢復)
- Auto-scale(根據流量自動擴縮)
託管付的代價
- Vendor lock-in(綁 Anthropic)
- 按 hour 計貴(高頻使用比自架貴 5-10 倍)
- Debug 黑箱(出事看不到細節)
何時值得託管
- 企業合規(SOC 2、HIPAA、FedRAMP)
- 上線時程壓力(自己架要 1-2 個月)
- 不想招運維人員
📊 監控:Agent 的 4 大特殊指標
Agent 需要一般 web app 監控,但還要加上 token、tool call、reasoning quality 與 context 相關指標。
指標 1:Token Rate(突然飆高 = bug)
正常範圍:100-1000 tokens / 分鐘 異常:突然飆到 10,000+ tokens / 分鐘
意義:Agent 可能進入無窮迴圈,正在燒錢**。
監控做法:
# 用 OpenTelemetry / Langfuse 記錄
def log_token_usage(tokens, agent_id):
metric.record(
"token_rate",
tokens,
tags={"agent_id": agent_id, "timestamp": now()}
)警報線:單分鐘 > 5,000 tokens → 立即通知
指標 2:Tool Call Success Rate
正常:> 95% 成功 異常:< 90% 表示工具或 schema 有問題
意義:Agent 可能 schema 寫錯、tool API 故障、權限不足。
監控做法:
- 每個 tool call 記錄 success / failure
- 按 tool 分類統計
- 失敗率 > 10% 就警報
指標 3:Reasoning Quality(hallucination 偵測)
這個最難測——需要結構化輸出 schema 驗證。
做法:
- 強制 JSON Schema 輸出——輸出不符 schema = 第一道警報
- 隨機 sample 人工 review(每 100 個 task review 1 個)
- Reflection pattern——Agent 設計模式 自我審視
指標 4:Context Length Distribution
正常:單次 task context 5K-50K 異常:單次 task context > 200K
意義:Context 設計有問題,可能是 context bleeding**(詳見 Multi-Agent Orchestration)。
工具推薦
| 工具 | 適合 | 月費 |
|---|---|---|
| Langfuse(開源) | 自架友善 | 自架 $5-20 |
| Helicone(SaaS) | 快速整合 | $25-100 |
| OpenTelemetry(通用) | 整合 Datadog / Grafana | 看後端 |
| Phoenix(Arize) | LLM 觀測專用 | 免費版可用 |
個人專案可以優先考慮 Langfuse 自架;團隊若想降低整合成本,Helicone 會比較快上手。
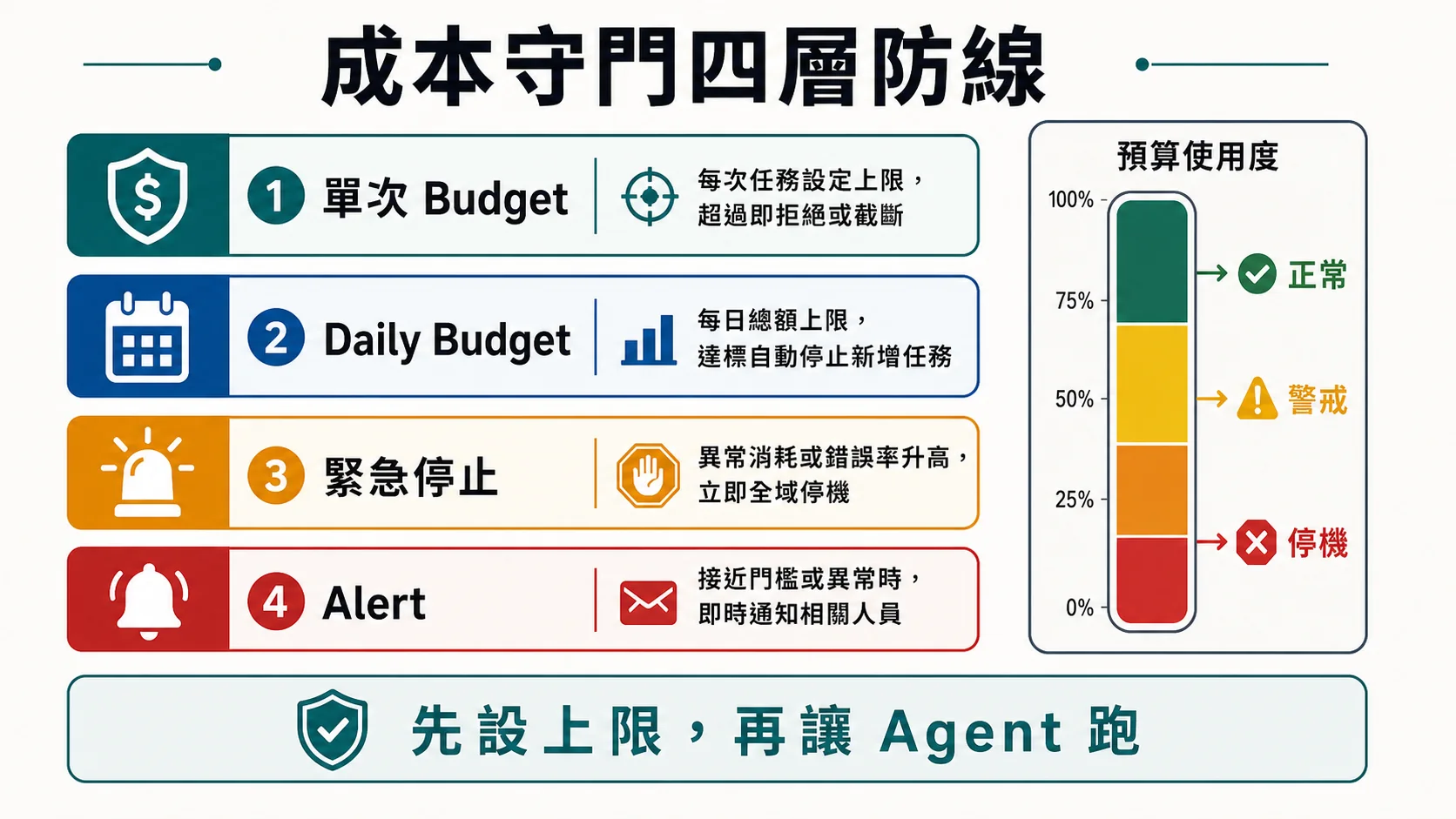
🛡️ 成本守門:4 層防線
成本守門是 agent production 的核心,因為模型呼叫、tool retry 與長迴圈都可能把小錯誤放大成帳單事故。
真實案例:Agent 一晚燒 200 USD
情境:第一版 triage agent 若寫出無窮迴圈,每次任務失敗就 retry,卻沒有設定 max_retries,就可能從半夜跑到早上,單日燒掉 $200。
怎麼防:4 層成本守門。
L1:單次 Budget(每 task 最高 token / 美金)
class TaskBudget:
def __init__(self, max_tokens=10000, max_cost=0.50):
self.max_tokens = max_tokens
self.max_cost = max_cost
self.spent_tokens = 0
self.spent_cost = 0
def can_continue(self):
return (self.spent_tokens < self.max_tokens
and self.spent_cost < self.max_cost)
def add_usage(self, tokens, cost):
self.spent_tokens += tokens
self.spent_cost += cost
if not self.can_continue():
raise BudgetExceeded(
f"Token: {self.spent_tokens}/{self.max_tokens}, "
f"Cost: ${self.spent_cost:.2f}/${self.max_cost:.2f}"
)典型設定:單 task $0.10-1.00,單 task 5K-50K tokens**
L2:Daily Budget(超 $20 強制停)
class DailyBudget:
def __init__(self, max_daily_cost=20):
self.max_daily_cost = max_daily_cost
self.daily_log = load_today_log()
def can_start_new_task(self):
return sum(self.daily_log.costs) < self.max_daily_cost典型設定:個人 $5-20/天,團隊 $50-200/天**
L3:緊急停止(失敗率 > 50% 自動關)
class FailureGuard:
def __init__(self, max_failure_rate=0.5, window=10):
self.results = [] # 最近 10 次結果
self.max_rate = max_failure_rate
self.window = window
def record_result(self, success):
self.results.append(success)
if len(self.results) > self.window:
self.results.pop(0)
if len(self.results) == self.window:
failure_rate = sum(1 for r in self.results if not r) / len(self.results)
if failure_rate > self.max_rate:
raise EmergencyStop(f"Failure rate {failure_rate}")L4:Alert(超過 80% budget 寄信)
def check_alert(spent, budget):
if spent / budget > 0.8:
send_email(
subject="⚠️ Agent budget 80% used",
body=f"Spent ${spent}/{budget} today"
)4 層合用範例
@with_budget(task_budget=TaskBudget(max_cost=0.50))
@with_daily_budget(DailyBudget(max_daily_cost=20))
@with_failure_guard(FailureGuard(max_failure_rate=0.5))
@with_alert(threshold=0.8)
def run_agent_task(task):
# 你的 agent 邏輯
...建議每個新 agent 都先實作這 4 層,再接正式資料與長時間排程,避免小 bug 變成長時間燒錢。
📋 Production 30 天驗收清單
Agent 上線後 30 天的觀察 SOP:
Day 1-3:基線觀察
- 每次 task 的 token、latency、success rate——建立 baseline
- Cost per task —— 典型範圍應穩定
- 沒有突然飆高 token
Day 4-7:壓測 + 邊界 case
- 故意餵 prompt injection(看 agent 是否被攻擊)
- 故意給空輸入 / 超長輸入
- 故意斷網 / 斷 API——觀察 retry 機制
Day 8-14:第一次優化
- 看 Day 1-7 數據,找最常用的 tool / 最貴的 sub-task**
- 該砍的 tool 砍掉(很少用又貴的)
- prompt caching 套用(熱門 system prompt)
Day 15-30:長期穩定性
- Memory leak 偵測(連續跑 7 天,memory 不該持續增長)
- Context drift——長期 agent 是否累積錯誤的「世界觀」)
- 跨日 / 跨週 pattern(週末跟工作日數據差異)
30 天後:3 選 1
- 正式 GA(穩定 → 推給更多用戶)
- 退役(沒 ROI → 砍掉)
- Pivot(改變方向,重新定義 agent)
第一版 agent 在 30 天內退役並不一定是失敗。若數據證明 ROI 不足,及早關掉反而是健康的迭代。
❓ FAQ
個人開發者真的需要 Docker 嗎?cron 不夠嗎?
90% 場景 cron 夠。
個人 agent 不需要套用企業級架構。若每天只跑少量任務,直接上 Docker 或 K8s 通常是過度工程。
真實情境:
- 個人 agent(每天跑 1-3 次):cron 完全夠
- 小團隊 / VPS(多人用):升 Docker
- 企業 / production SaaS:才考慮 K8s
排程型個人 agent 若任務穩定、log 清楚、成本可控,長期使用 cron 仍是務實選擇。
Agent 一個月跑下來多少錢?
分三級:
個人輕度(每天 1 次,單次 5K tokens):
- LLM API:$5-20/月
- 主機:$0(本機 cron)
- 總:$5-20
接案 / 小團隊(每天多次):
- LLM API:$50-150/月
- VPS:$10-20/月
- 監控:$0-25/月
- 總:$60-200
Production / 服務客戶(24/7):
- LLM API:$200-2000/月(視流量)
- 雲端 / K8s:$50-300/月
- 監控 stack:$25-100/月
- 總:$300-2,400
個人低頻 agent:若只是每日排程與少量任務,月帳單有機會壓在 $10 以內。
怎麼防止 agent 失控燒錢?
4 層成本守門:
- L1 單次 budget:每 task $0.10-1.00 上限
- L2 daily budget:$5-20/天上限,超過 hard stop**
- L3 緊急停止:失敗率 > 50% 自動關
- L4 alert:80% budget 寄 email + Slack
若沒有這 4 層防線,第一版 agent 很容易因 retry、迴圈或 tool failure 在一晚燒掉 $200。新 agent 應先完成成本守門再上線。
程式碼範例見上方第 5 節。
Agent 監控跟一般 web app 監控差在哪?
4 大 Agent 特殊指標(web app 沒有):
- Token Rate(突然飆 = bug)
- Tool Call Success Rate(< 90% = 工具壞)
- Reasoning Quality(hallucination 偵測)
- Context Length Distribution(爆量 = 設計問題)
Web app 也要監控(CPU / memory / latency)仍須做——但這 4 個是 agent 獨有。
工具推薦:
- Langfuse(開源,LLM 觀測專用)
- Helicone(SaaS,快速整合)
- Phoenix(Arize,hallucination 偵測強)
我該自己架還是用 Claude Managed Agents?
看 4 個維度:
| 維度 | 自架 | Claude Managed |
|---|---|---|
| 上線時程 | 1-2 個月 | 1 週 |
| 成本(高頻) | 便宜 5-10 倍 | 按 hour 計貴 |
| 合規 | 自己扛 | Anthropic 扛(SOC 2 等) |
| Debug | 看 source code | 黑箱 |
該選 Claude Managed 的情境:
- 企業合規嚴(銀行、醫療、政府)
- 上線時程壓力(老闆要 1 週)
- 不想招運維
該自架的情境:
- 個人 / 小團隊(成本敏感)
- 需要極端客製化
- 不擔心合規
⚠️ 警語
- 本文 4 階段路徑 + 成本守門 + 監控是實務部署檢查表,production 仍可能出現意外
- 無 Sandbox 跑 CodeAct = pocketos 事件再現——對應 Pocketos 9 秒刪庫
- 企業合規 production agent——請諮詢 IT / 合規顧問(SOC 2 / HIPAA / FedRAMP 等)
權威來源:
深入閱讀:➜ AI Agent Pillar | Agent 設計模式 | Multi-Agent Orchestration | AI 月費省錢手冊