為什麼你需要懂 Agent 設計模式
80/20 法則:用對模式 = 80% 的 production 穩定度。
繁中 SERP 上「Agent 設計模式」文章分兩類:
- 學術派:只列 paper 定義(ReAct paper、Reflexion paper)——不講「何時用」
- 業配派:鼓吹「全用 Multi-Agent」——沒人說 90% 場景單 agent 就夠
最大內容空缺:沒人給「何時用哪個」決策樹** + 同任務跑 5 模式實測對照。
這篇是 2026 年 Agent 設計模式的地圖(不是論文)——讓你看完就會判斷「這個任務該用哪個」。
🎯 7 大設計模式速覽
| 模式 | 一句話定義 | 適用場景 | Production 成熟度 |
|---|---|---|---|
| 🔄 ReAct (Reasoning + Acting) | 思考 → 行動 → 觀察 → 再思考的迴圈,每一步基於最新狀態決策 | 工具呼叫不確定性高、需錯誤即時修正(客服、研究、日常 agent)——production 用最多 | ⭐⭐⭐⭐⭐ |
| 🗺️ Plan-and-Execute | 先寫完整計畫,再逐步執行,計畫和執行解耦** | 計畫穩定可預測、想用便宜 LLM 跑執行階段(企業流程、報告生成) | ⭐⭐⭐⭐ |
| ⚡ ReWOO (Reasoning Without Observation) | 規劃時不等觀察結果,所有 tool call 平行送出,最後合成 | 工具獨立性高、追求低 latency(搜尋、資料抓取)——省 50-70% latency | ⭐⭐⭐⭐ |
| 💻 CodeAct | 不選 tool,直接讓 LLM 寫 code 解問題 | 計算密集、邏輯複雜、tool 列表太長(資料分析、數學)——Apple 力推、多步準確率 +20% | ⭐⭐⭐ |
| 🪞 Reflection (Reflexion) | 產出後自我審查,找出問題 → 改正 → 再產出 | 品質第一、可多花 token(寫作、code review、研究)——HumanEval 80→91% | ⭐⭐⭐⭐ |
| 🌳 Tree of Thoughts (ToT) | 同時展開多條思考路徑,評估後選最好的 | 創意 / 多解法問題、puzzle / 規劃題、不確定哪條路對 | ⭐⭐(學術為主) |
| 👥 Multi-Agent | 多個專家 agent 分工協作(由 coordinator 編排) | 複雜任務可拆解、不同領域需要不同專家(研究 / 編譯 / 開發)——詳見 multi-agent orchestration | ⭐⭐⭐⭐ |
🌳 模式選擇決策樹
5 個 yes/no 問題,走完知道該用哪個模式:
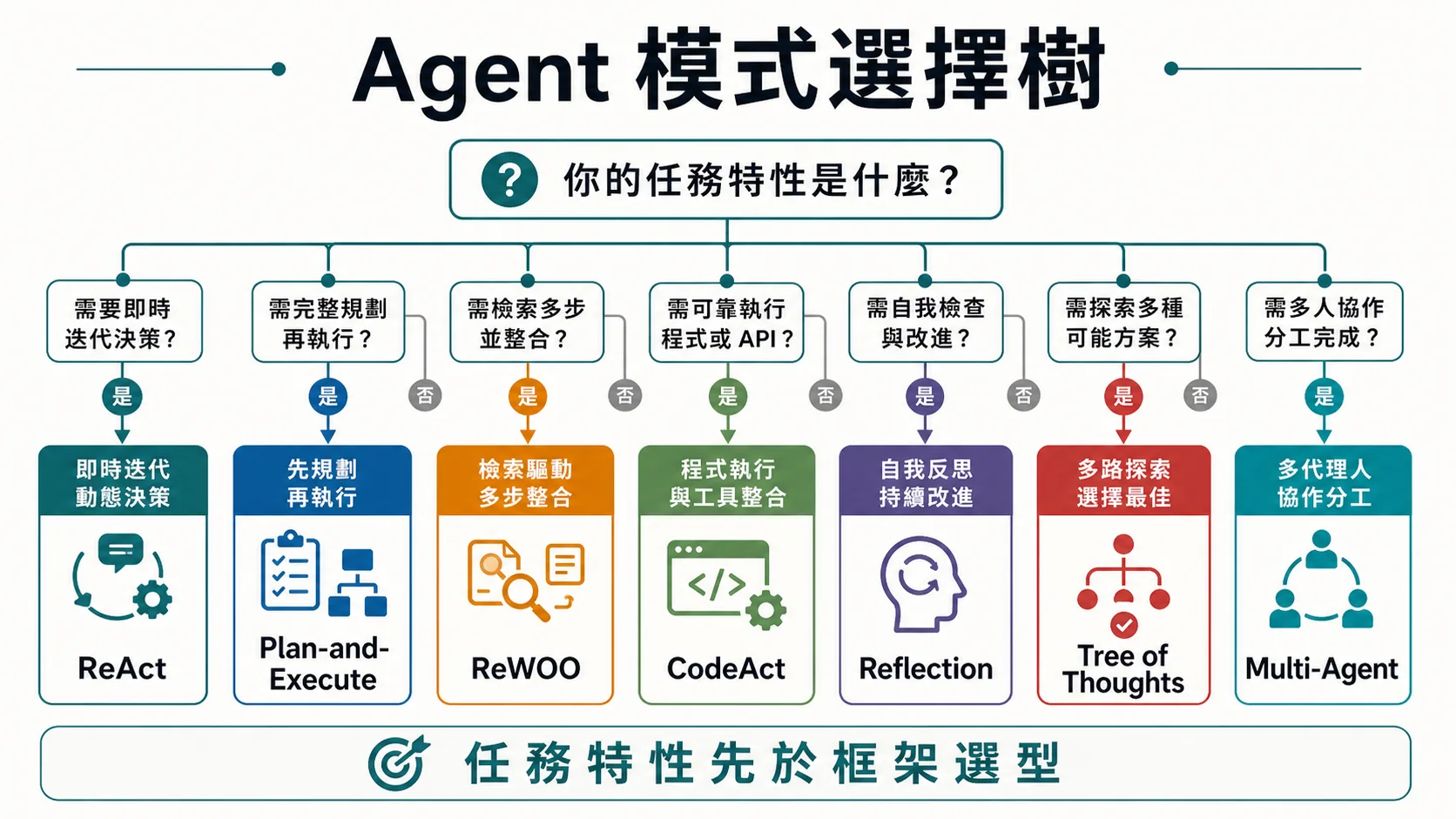
Q1:任務可以「**先想完整計畫再執行**」**嗎?(計畫穩定可預測)
├── YES → Plan-and-Execute(主) / 看 Q2
└── NO → ReAct(主)
Q2:tool call 之間有相依性嗎?(後一個需要前一個的結果)
├── NO,**可平行** → ReWOO(主)
└── YES → 看 Q3
Q3:需要極高品質(願意多花 token)?
├── YES → 加 Reflection(套在 ReAct / Plan 之上)
└── NO → 看 Q4
Q4:任務需要複雜計算或邏輯(超過 tool 能做)?
├── YES → 加 CodeAct(讓 LLM 寫 code 解)
└── NO → 看 Q5
Q5:任務可拆給多位「**專家 agent**」**做?
├── YES → Multi-Agent
└── NO → 單 agent + 對應上述模式Mason 反潮流主張:「90% 場景從 ReAct 開始就對了」——對手鼓吹「全用 Multi-Agent」的多半是學術派或業配,真實 production 簡單最穩。
🧪 同任務 5 模式實測對照
任務:「爬一篇 AI 新聞 + 摘要 + 打分」(Mason 自己 agent 的子任務,詳見 ai-agent-self-build-mcp-2026)
| 模式 | Token 消耗 | 時間 | 準確率 | 適用性 |
|---|---|---|---|---|
| ReAct | ~3,000 | 12 秒 | 92% | ✅ 最平衡 |
| Plan-and-Execute | ~2,500 | 18 秒 | 90% | 🟡 計畫穩定才有優勢 |
| ReWOO | ~2,000 | 6 秒 | 88% | ✅ 速度最快 |
| Reflection(套 ReAct) | ~6,000 | 24 秒 | 97% | ✅ 品質最高 |
| CodeAct | ~4,000 | 15 秒 | 85% | 🔴 這任務不適合(無計算需求) |
結論:沒有最好的模式,只有最適合任務的模式。
- 快:ReWOO(2,000 token、6 秒)
- 準:Reflection(97%,但 token × 3)
- 平衡:ReAct(主力)
- 不適合:CodeAct(這任務沒計算需求)
🔄 ReAct 深度:80% production 用這個
ReAct = Reasoning + Acting——思考 → 行動 → 觀察 → 再思考的迴圈。
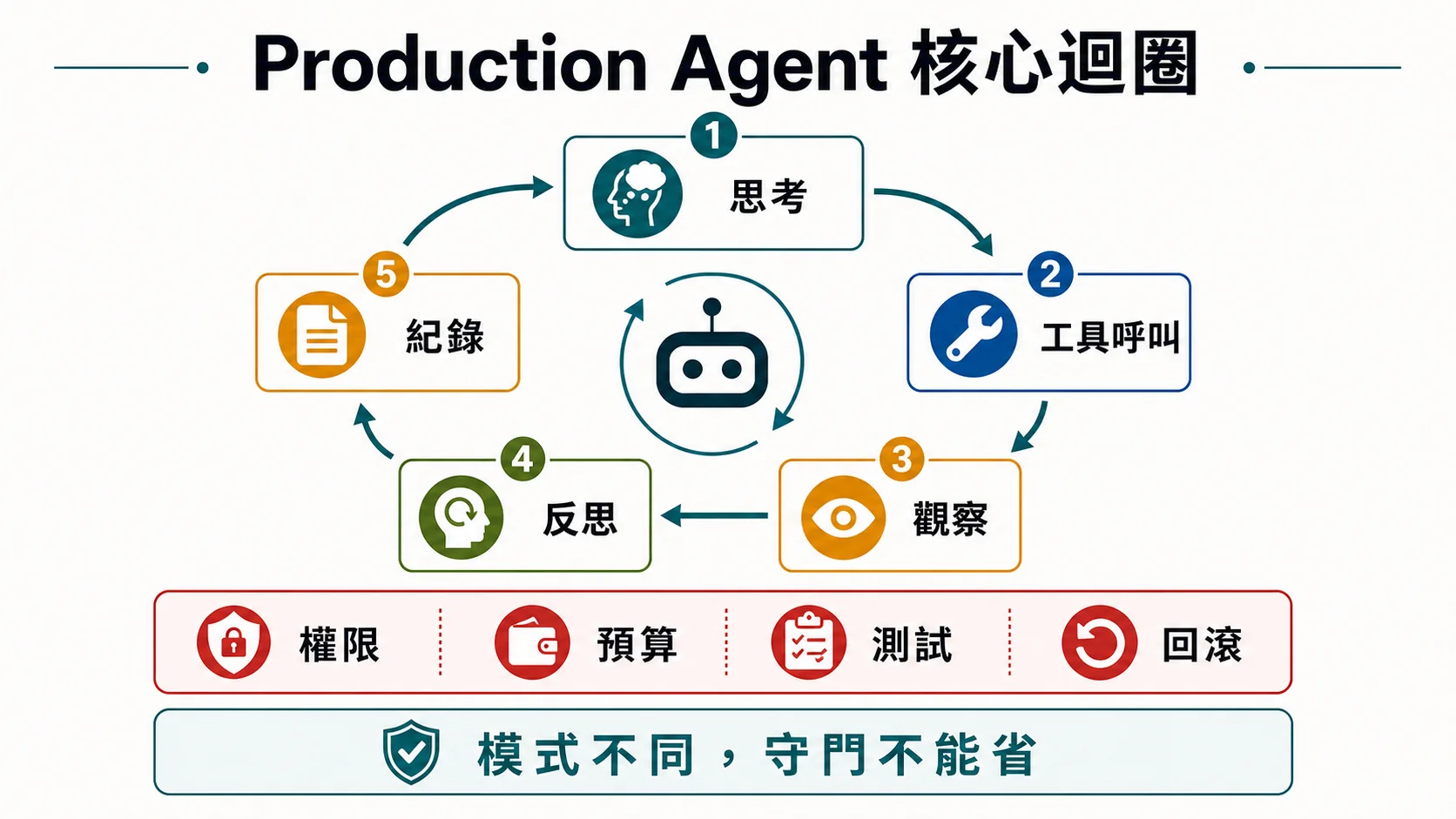
為什麼 ReAct 是 production 主力
3 個優勢:
- 錯誤即時修正——每步基於最新狀態決策,錯了下一步就改
- 彈性——不需要預先知道完整流程
- debug 容易——每步都有 trace
核心迴圈
def react_agent(task):
messages = [{"role": "user", "content": task}]
for iteration in range(max_iterations):
# Reason
response = llm.generate(messages, tools=tools)
if response.is_done:
return response.final_answer
# Act
tool_result = execute_tool(response.tool_call)
# Observe
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "tool", "content": tool_result})
raise Exception("Max iterations exceeded")Production 細節
必設 3 個保護:
max_iterations= 10-20(防無窮迴圈)max_cost_per_task= $1(防失控燒錢)escape_hatch= 3 步沒進展 → 主動停 + 回報
🗺️ Plan-and-Execute:計畫穩定才有優勢
核心:先寫完整計畫,再逐步執行——計畫和執行解耦**。
何時用
- 流程可預測(例如「每週生成銷售報告」)
- 想用便宜模型跑執行階段(Plan 用 Opus,Execute 用 Haiku)
何時不用
- 流程多變(用 ReAct 即時調整更穩)
- 計畫常需修改(Plan-and-Execute 一旦計畫錯,整個崩)
範例
def plan_and_execute(task):
# Plan 階段(用強模型)
plan = strong_llm.generate(f"請列出完成 {task} 的步驟", model="opus-4-7")
# Execute 階段(用便宜模型)
results = []
for step in plan.steps:
result = cheap_llm.execute(step, model="haiku-4-5")
results.append(result)
return synthesize(results)⚡ ReWOO:平行省 50-70% latency
核心:規劃時不等觀察結果,所有 tool call 平行送出,最後合成。
為什麼快
ReAct 序列:tool1 (3s) → tool2 (3s) → tool3 (3s) = 9 秒
ReWOO 平行:[tool1, tool2, tool3] 平行 = 3 秒
何時用
- tool call 獨立(沒有後依賴前)
- 想壓低 latency
何時不用
- tool 之間有相依性(後一個 tool 需要前一個結果)
- 預算敏感(ReWOO 平行 = 同時多個 LLM call,token 倍數增加)
限制
- 錯誤無法即時修正——平行送出後才合成,過程錯誤要事後處理
- 不能跟 Reflection 混用(下面詳述)
💻 CodeAct:LLM 寫 code 解問題
核心:不選 tool,直接讓 LLM 寫 Python / JavaScript code 在 sandbox 執行。
為什麼強
Apple 研究(2024 Berkeley + UIUC):CodeAct 在多步任務準確率比傳統 tool use 高 20%——因為 LLM 寫 code 比選 tool 更自由。
範例
任務:「找出 2026/01-05 哪些月的 AI 新聞最多?」
傳統 ReAct:逐月查、累加、比較——5 步
CodeAct:LLM 直接寫
months = ['2026-01', '2026-02', '2026-03', '2026-04', '2026-05']
counts = {m: count_news(month=m) for m in months}
return max(counts, key=counts.get)Production 必加
🔴 Sandbox——LLM 寫的 code 直接執行 = 巨大風險。必須在 Docker / E2B / Modal 等隔離環境。
白名單套件——不准 import os、subprocess、shutil(可能刪檔)。
對應警語:pocketos 9 秒刪庫事件——CodeAct 沒 sandbox 就是 pocketos 再現。
🪞 Reflection:HumanEval 80→91%
核心:產出後自我審查——找出問題 → 改正 → 再產出。
為什麼強
Reflexion 論文(2023 Northeastern):HumanEval 從 80%(GPT-4 baseline)→ 91%(加 Reflection)——4% 任務翻盤關鍵。
範例工作流
def reflection_agent(task):
output = react_agent(task) # 初版
for i in range(max_reflections): # 最多 3 輪
critique = llm.evaluate(output, criteria=quality_criteria)
if critique.score >= threshold:
return output
output = react_agent(task, feedback=critique.feedback)
return outputProduction 必加
score_threshold= 0.8(避免無限反思)max_reflections= 3(token 上限保護)- stopping criteria:連續 2 輪 score 沒進步 → 停
🌳 Tree of Thoughts(學術為主)
核心:同時展開多條思考路徑,評估後選最好的——像下棋的 minimax。
為什麼仍是學術為主
Production 用 ToT 的 3 個問題:
- token 倍數爆炸(每條路徑都要算)
- latency 高(等所有路徑跑完才能選)
- 真實任務的「多解法」不像 puzzle 那麼明確**
何時值得試
- 複雜謎題 / 規劃題(數獨、creative writing、math olympiad)
- 預算寬鬆 + 對品質有極高要求
Mason 的觀察:99% production 不需要 ToT——Reflection 已能滿足品質需求。
👥 Multi-Agent:複雜任務分工
深度教學:Multi-Agent Orchestration 完整指南
核心:多個專家 agent 分工協作(由 coordinator 編排)。
何時用
- 任務可清楚拆解(研究 / 編譯 / 開發是不同專家)
- 不同領域需要不同 system prompt / 工具
- 預算允許(token 倍數 × 通常 4-7 倍)
何時不用
- 任務簡單(80% 場景單 agent 夠用)
- 預算緊(multi-agent 是「最貴的 agent」)
🧩 模式組合矩陣(SERP 沒人寫過)
這節是這篇文章對 SERP 最有殺傷力的章節——對手都只講單一模式。
7×7 相容 / 衝突表
| ReAct | Plan&Exec | ReWOO | CodeAct | Reflection | ToT | Multi-Agent | |
|---|---|---|---|---|---|---|---|
| ReAct | — | 🟡 二選一 | 🔴 衝突 | ✅ 可合 | ✅ 經典 | ⚠️ 重複功能 | ✅ 可內嵌 |
| Plan&Exec | 🟡 | — | ✅ 可合 | ✅ 可合 | ✅ 可合 | ⚠️ | ✅ 可合 |
| ReWOO | 🔴 | ✅ | — | ✅ 可合 | 🔴 衝突 | 🔴 衝突 | ✅ 可合 |
| CodeAct | ✅ | ✅ | ✅ | — | ✅ 可合 | ⚠️ | ✅ 可合 |
| Reflection | ✅ 經典 | ✅ | 🔴 衝突 | ✅ | — | ⚠️ | ✅ 可合 |
| ToT | ⚠️ | ⚠️ | 🔴 衝突 | ⚠️ | ⚠️ | — | ⚠️ |
| Multi-Agent | ✅ 內嵌 | ✅ | ✅ | ✅ | ✅ | ⚠️ | — |
經典組合(production 真在用)
1. ReAct + Reflection = Devin / Claude Code 的設計
做法:ReAct 每步思考行動,Reflection 在重要節點 self-review**。 效益:HumanEval 等級的準確率提升 + ReAct 的彈性。
2. Multi-Agent + ReAct = Anthropic Claude Managed 預設架構
做法:Coordinator 規劃 + 每個 sub-agent 用 ReAct 執行。 效益:分工 + 每個 sub-agent 都有錯誤修正能力。
3. Plan-and-Execute + ReWOO = 大型企業流程最省解
做法:Plan 寫好步驟,ReWOO 平行執行能平行的部分。 效益:省 latency + 省 token**。
4. CodeAct + Sandbox + Reflection = AI 資料分析
做法:LLM 寫 code,Sandbox 跑,Reflection 檢查結果合理。 效益:複雜計算 + 結果驗證。
衝突組合(別這樣搭)
🔴 ReWOO + Reflection — 邏輯衝突
為什麼:ReWOO 是平行(不等觀察),Reflection 需要看完結果才能審查——兩者哲學相反。
🔴 ReAct + ReWOO — 設計衝突
為什麼:ReAct 是序列(基於觀察決策),ReWOO 是平行(不等觀察)——不能同時用。
⚠️ ToT + 任何其他 — token 爆炸
為什麼:ToT 本身 token 已多倍,加其他模式 = 倍中倍。
🛡️ 每個模式的 Production 細節
ReAct
max_iterations= 10-20escape_hatch= 3 步沒進展自動停- tool schema 強約束(JSON Schema 驗證)
Plan-and-Execute
- plan 序列化儲存(中途可 resume)
- re-plan 觸發:某步失敗 N 次 → 重新規劃
ReWOO
- placeholder 驗證:parallel 結果回來後檢查格式
- failure handling:一個 tool 失敗 → fallback / retry
CodeAct
- 🔴 Sandbox 必備(Docker / E2B / Modal)
- 套件白名單(不准
os、subprocess、shutil) - 時間限制(單次執行 < 30 秒)
Reflection
reflection_cap= 3(不能無限反思)score_threshold= 0.8(達標就停)- stopping criteria:連續 2 輪 score 沒進步 → 停
Tree of Thoughts
- branch limit = 5(別開太多支)
- depth limit = 3
- evaluation cost cap(評估也燒 token)
Multi-Agent
🛠️ 模式 vs Framework 對照
哪個框架原生支援哪個模式?
| 模式 | LangGraph | CrewAI | AutoGen | Claude Agent SDK |
|---|---|---|---|---|
| ReAct | ✅ 原生 | ✅ 原生 | ✅ 原生 | ✅ 最佳 |
| Plan-and-Execute | ✅ 原生 | 🟡 需自寫 | 🟡 | ✅ |
| ReWOO | ✅ 原生 | 🟡 | 🟡 | 🟡 需自寫 |
| CodeAct | ✅ 原生 | 🟡 | 🟡 | ✅ |
| Reflection | ✅ 原生 | ✅ | ✅ 強 | ✅ |
| ToT | ✅ 原生 | 🟡 | 🟡 | 🟡 |
| Multi-Agent | ✅ 最佳 | ✅ 角色明確 | ✅ 辯論型 | ✅ |
選 framework 的建議:
- 想全模式都用 → LangGraph(原生支援最完整)
- 角色明確、業務人也能改 → CrewAI
- 辯論 / 嚴謹決策 → AutoGen
- 貼 Claude + 輕量 + MCP 友善 → Claude Agent SDK
🔮 2026 之後新興模式(預告)
Persistent Memory Agent(Hermes-style)
自我進化 + 跨 session 累積經驗——對應 Hermes Agent。
Tool-Synthesis Agent
Agent 寫自己需要的 tool——不需事先定義 tool list。
Self-Healing Agent
Agent 自己偵測異常 + 修復——production 故障自動 hotfix。
Subconscious Dreaming
Anthropic 2026/05 Claude Managed 新功能——對應 code-with-claude-2026-dreaming-multiagent。
❓ FAQ
ReAct 跟 Chain-of-Thought(CoT)差在哪?
CoT 純推理:「讓我想想」——LLM 自己內部思考,沒有外部工具。
ReAct = CoT + Tool Use:思考 → 用工具 → 觀察結果 → 再思考——有外部世界互動。
典型差異:
- 問「2 + 2 = ?」 → CoT 夠(LLM 內部算)
- 問「昨天台北天氣?」 → 必須 ReAct(需呼叫天氣 API)
Mason 的觀察:所有 production agent 都用 ReAct——CoT 只在純推理任務(數學、邏輯)有用。
為什麼 ReWOO 比 ReAct 快這麼多?
因為平行:
ReAct 序列:tool1 (3s) → tool2 (3s) → tool3 (3s) = 9 秒
ReWOO 平行:[tool1, tool2, tool3] 一起送 = 3 秒
典型 latency 改善:50-70%
但 ReWOO 有 2 個前提:
- tool 之間獨立(無相依性)
- 不需要錯誤即時修正(因為平行已送出)
典型適用:搜尋、資料抓取、批次摘要——不適用客服、研究、迭代任務。
Reflection 真的能改善準確率嗎?還是燒 token 而已?
兩者皆是——準確率上升 + token 倍增。
Reflexion 論文數據:
- HumanEval(程式碼):80% → 91%(+11%)
- Token 消耗:通常 2-4 倍
該用 Reflection 的場景:
- 品質第一(寫作、code review、研究報告)
- 預算寬鬆(願意 3-4 倍 token)
- 任務「自我審視有意義」(數學題答錯能看出來)
不該用的場景:
- 任務「自己看不出對錯」(例如創意寫作的好壞主觀)
- 預算緊
Mason 的建議:production code review、合約審視、重要報告 → 用 Reflection;日常任務 → ReAct 夠用。
CodeAct 安全嗎?LLM 直接寫程式碼跑?
沒 sandbox = 極危險——對應 pocketos 9 秒刪庫事件。
production CodeAct 必加:
- Sandbox(Docker / E2B / Modal / 公司自架)——檔案系統隔離
- 套件白名單——禁用
os、subprocess、shutil、requests(讓 LLM 用受控 API) - 時間限制——單次執行 < 30 秒(防無窮迴圈)
- 資源限制——memory < 1GB、CPU < 1 core
Anthropic Claude Computer Use 跟 Claude Managed Agents 都用 sandbox——這是業界共識。
個人開發者:用 E2B / Modal 等 sandbox SaaS——月費 $20-50 比自架便宜。
我同時用 ReAct + Reflection + Multi-Agent 可以嗎?
可以,這是 production 經典三明治**。
架構:
- Multi-Agent 最外層:Coordinator 規劃 + 派發給 sub-agents
- 每個 sub-agent 用 ReAct:思考 → 行動 → 觀察 → 再思考
- Coordinator 用 Reflection:檢查 sub-agents 的結果是否合理
真實案例:Anthropic Claude Managed Agents 預設架構就是這個三明治。
衝突點要注意:
- 絕對不能加 ReWOO(跟 ReAct 衝突)
- 絕對不能加 ToT(跟 Reflection 重複功能)
完整組合矩陣 → 看上面 7×7 表。
⚠️ 警語
- 本文 7 模式覆蓋 production 90% 場景——但學術界仍有許多新興模式(2026 後會出現新的)
- 每個模式的 Production 細節(max_iterations、sandbox、score threshold)是必要的——不加 = 失控風險
- CodeAct 沒 sandbox = pocketos 事件再現——安全第一
權威來源:
- ReAct paper(2022 Princeton)
- Reflexion paper(2023 Northeastern)
- CodeAct paper(2024 Berkeley + UIUC)
- Tree of Thoughts(2023 Princeton + Google)
深入閱讀:➜ AI Agent 完整指南 Pillar | AI Agent 從零自建 | Multi-Agent Orchestration | Agent Production 部署